Hi @gmarkall, really appreciate the quick reply! For the two optimization strategies you suggest, I setnumba.config.CUDA_ARRAY_INTERFACE_SYNC = False and do the profiling with or without a configured kernel.
The performance changed from 219ms (no configured kernel, with sync=True) to 158ms (no configured kernel with sync=False) and 147ms (configured kernel with sync=True).
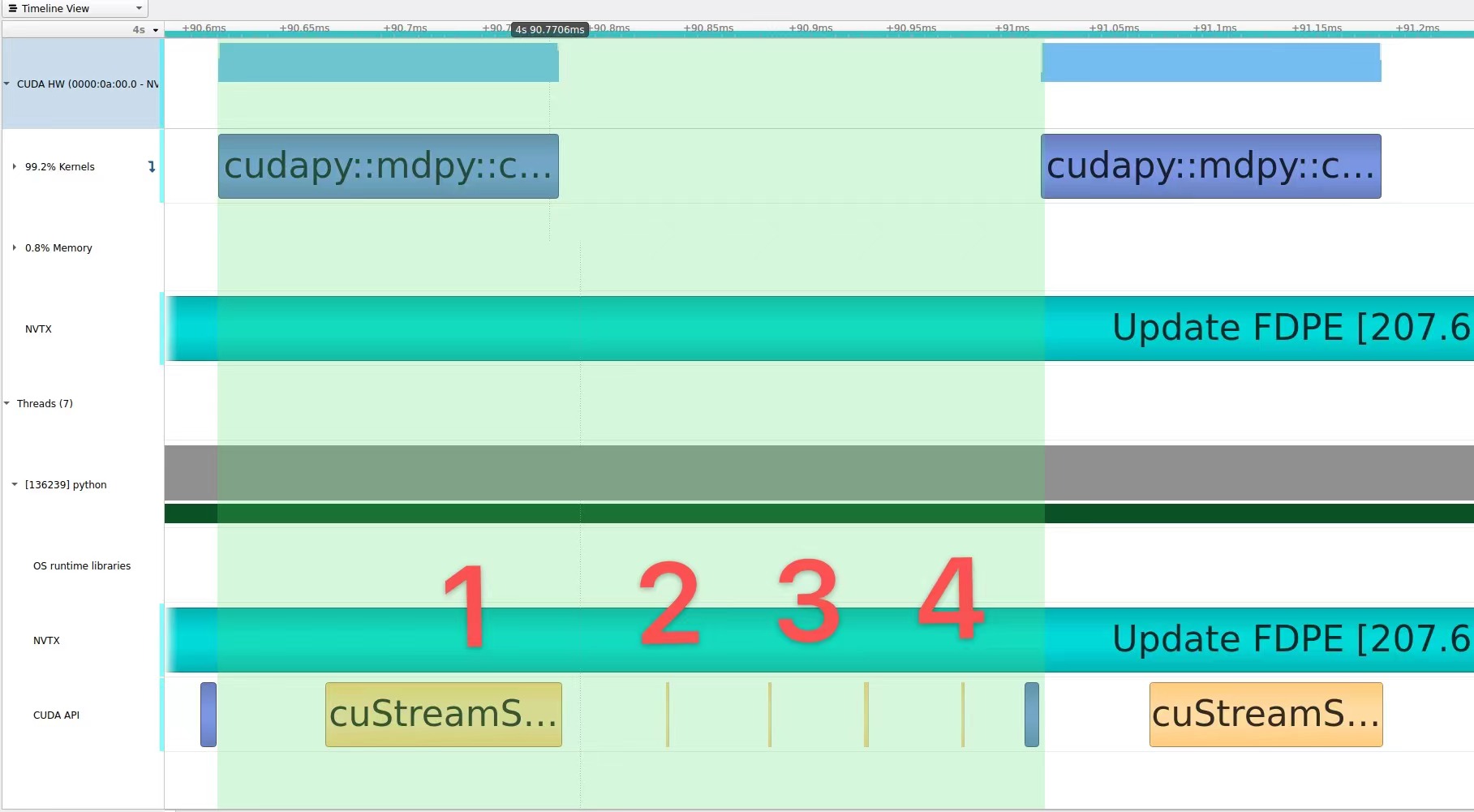
It seems that the sync behavior has a big influence. However, I found the kernel gap disappears for the launching of the first serval loops and then appears again.
, while the gap shrinks from 250us to 150us, which is still comparable to the kernel execution time. The change of gap time is really strange for me. And there is no other Cuda API calling between the gap.
Here I give the code of the target kernel:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
file : repro.py
created time : 2022/06/27
author : Zhenyu Wei
version : 1.0
contact : zhenyuwei99@gmail.com
copyright : (C)Copyright 2021-2021, Zhenyu Wei and Southeast University
"""
import numpy as np
import cupy as cp
import numba as nb
import numba.cuda as cuda
from cupy.cuda.nvtx import RangePush, RangePop
GRID_POINTS_PER_BLOCK = 8 # 8*8*8 grids point will be solved in one block
TOTAL_POINTS_PER_BLOCK = GRID_POINTS_PER_BLOCK + 2 # 10*10*10 neighbors are needed
nb.config.CUDA_ARRAY_INTERFACE_SYNC = False
@cuda.jit(
nb.void(
nb.float32[:, :, ::1], # relative_permittivity_map
nb.float32[:, :, ::1], # coulombic_electric_potential_map
nb.float32[::1], # cavity_relative_permittivity
nb.int32[::1], # inner_grid_size
nb.float32[:, :, ::1], # reaction_field_electric_potential_map
)
)
def solve_equation(
relative_permittivity_map,
coulombic_electric_potential_map,
cavity_relative_permittivity,
inner_grid_size,
reaction_field_electric_potential_map,
):
# Local index
local_thread_index = cuda.local.array((3), nb.int32)
local_thread_index[0] = cuda.threadIdx.x
local_thread_index[1] = cuda.threadIdx.y
local_thread_index[2] = cuda.threadIdx.z
# Global index
global_thread_index = cuda.local.array((3), nb.int32)
global_thread_index[0] = local_thread_index[0] + cuda.blockIdx.x * cuda.blockDim.x
global_thread_index[1] = local_thread_index[1] + cuda.blockIdx.y * cuda.blockDim.y
global_thread_index[2] = local_thread_index[2] + cuda.blockIdx.z * cuda.blockDim.z
# Grid size
grid_size = cuda.local.array((3), nb.int32)
for i in range(3):
grid_size[i] = inner_grid_size[i]
if global_thread_index[i] >= grid_size[i]:
return
# Neighbor array index
local_array_index = cuda.local.array((3), nb.int32)
for i in range(3):
local_array_index[i] = local_thread_index[i] + nb.int32(1)
# Shared array
shared_relative_permittivity_map = cuda.shared.array(
(TOTAL_POINTS_PER_BLOCK, TOTAL_POINTS_PER_BLOCK, TOTAL_POINTS_PER_BLOCK),
nb.float32,
)
shared_coulombic_electric_potential_map = cuda.shared.array(
(TOTAL_POINTS_PER_BLOCK, TOTAL_POINTS_PER_BLOCK, TOTAL_POINTS_PER_BLOCK),
nb.float32,
)
shared_reaction_field_electric_potential_map = cuda.shared.array(
(TOTAL_POINTS_PER_BLOCK, TOTAL_POINTS_PER_BLOCK, TOTAL_POINTS_PER_BLOCK),
nb.float32,
)
# Load self point data
shared_relative_permittivity_map[
local_array_index[0], local_array_index[1], local_array_index[2]
] = relative_permittivity_map[
global_thread_index[0], global_thread_index[1], global_thread_index[2]
]
shared_coulombic_electric_potential_map[
local_array_index[0], local_array_index[1], local_array_index[2]
] = coulombic_electric_potential_map[
global_thread_index[0], global_thread_index[1], global_thread_index[2]
]
shared_reaction_field_electric_potential_map[
local_array_index[0], local_array_index[1], local_array_index[2]
] = reaction_field_electric_potential_map[
global_thread_index[0], global_thread_index[1], global_thread_index[2]
]
# Load boundary point
for i in range(3):
if local_thread_index[i] == 0:
tmp_local_array_index = local_array_index[i]
tmp_global_thread_index = global_thread_index[i]
local_array_index[i] = 0
global_thread_index[i] -= 1
shared_relative_permittivity_map[
local_array_index[0], local_array_index[1], local_array_index[2]
] = relative_permittivity_map[
global_thread_index[0],
global_thread_index[1],
global_thread_index[2],
]
shared_coulombic_electric_potential_map[
local_array_index[0], local_array_index[1], local_array_index[2]
] = coulombic_electric_potential_map[
global_thread_index[0],
global_thread_index[1],
global_thread_index[2],
]
shared_reaction_field_electric_potential_map[
local_array_index[0], local_array_index[1], local_array_index[2]
] = reaction_field_electric_potential_map[
global_thread_index[0],
global_thread_index[1],
global_thread_index[2],
]
local_array_index[i] = tmp_local_array_index
global_thread_index[i] = tmp_global_thread_index
elif local_array_index[i] == GRID_POINTS_PER_BLOCK or global_thread_index[
i
] == (grid_size[i] - nb.float32(1)):
# Equivalent to local_thread_index[i] == GRID_POINTS_PER_BLOCK - 1
tmp_local_array_index = local_array_index[i]
tmp_global_thread_index = global_thread_index[i]
local_array_index[i] += 1
global_thread_index[i] += 1
global_thread_index[i] *= nb.int32(global_thread_index[i] != grid_size[i])
shared_relative_permittivity_map[
local_array_index[0], local_array_index[1], local_array_index[2]
] = relative_permittivity_map[
global_thread_index[0],
global_thread_index[1],
global_thread_index[2],
]
shared_coulombic_electric_potential_map[
local_array_index[0], local_array_index[1], local_array_index[2]
] = coulombic_electric_potential_map[
global_thread_index[0],
global_thread_index[1],
global_thread_index[2],
]
shared_reaction_field_electric_potential_map[
local_array_index[0], local_array_index[1], local_array_index[2]
] = reaction_field_electric_potential_map[
global_thread_index[0],
global_thread_index[1],
global_thread_index[2],
]
local_array_index[i] = tmp_local_array_index
global_thread_index[i] = tmp_global_thread_index
cuda.syncthreads()
# Load constant
cavity_relative_permittivity = cavity_relative_permittivity[0]
# Calculate
new_val = nb.float32(0)
denominator = nb.float32(0)
# Self term
self_relative_permittivity = shared_relative_permittivity_map[
local_array_index[0],
local_array_index[1],
local_array_index[2],
]
self_coulombic_electric_potential = shared_coulombic_electric_potential_map[
local_array_index[0],
local_array_index[1],
local_array_index[2],
]
new_val += (
nb.float32(6) * cavity_relative_permittivity * self_coulombic_electric_potential
)
# Neighbor term
for i in range(3):
for j in [-1, 1]:
local_array_index[i] += j
relative_permittivity = nb.float32(0.5) * (
self_relative_permittivity
+ shared_relative_permittivity_map[
local_array_index[0],
local_array_index[1],
local_array_index[2],
]
)
new_val += (
relative_permittivity
* shared_reaction_field_electric_potential_map[
local_array_index[0],
local_array_index[1],
local_array_index[2],
]
)
new_val += shared_coulombic_electric_potential_map[
local_array_index[0],
local_array_index[1],
local_array_index[2],
] * (relative_permittivity - cavity_relative_permittivity)
denominator += relative_permittivity
local_array_index[i] -= j
# Update
new_val /= denominator
new_val -= self_coulombic_electric_potential
old_val = reaction_field_electric_potential_map[
global_thread_index[0],
global_thread_index[1],
global_thread_index[2],
]
cuda.atomic.add(
reaction_field_electric_potential_map,
(
global_thread_index[0],
global_thread_index[1],
global_thread_index[2],
),
nb.float32(0.9) * new_val - nb.float32(0.9) * old_val,
)
if __name__ == "__main__":
inner_grid_size = [100, 100, 100]
device_inner_grid_size = cp.array(inner_grid_size)
device_relative_permittivity_map = cp.ones(inner_grid_size, cp.float32)
device_coulombic_electric_potential_map = cp.ones(inner_grid_size, cp.float32)
device_cavity_relative_permittivity = cp.ones([1], cp.float32)
device_reaction_filed_electric_potential_map = cp.zeros(inner_grid_size, cp.float32)
thread_per_block = (
GRID_POINTS_PER_BLOCK,
GRID_POINTS_PER_BLOCK,
GRID_POINTS_PER_BLOCK,
)
block_per_grid = (
int(np.ceil(inner_grid_size[0] / GRID_POINTS_PER_BLOCK)),
int(np.ceil(inner_grid_size[1] / GRID_POINTS_PER_BLOCK)),
int(np.ceil(inner_grid_size[2] / GRID_POINTS_PER_BLOCK)),
)
RangePush("Configure Kernel")
configured_kernel = solve_equation[block_per_grid, thread_per_block]
RangePop()
RangePush("Update")
for _ in range(500):
configured_kernel(
device_relative_permittivity_map,
device_coulombic_electric_potential_map,
device_cavity_relative_permittivity,
device_inner_grid_size,
device_reaction_filed_electric_potential_map,
)
RangePop()
Hope it may help!
Best,