Well, hello guys
I’m trying to make a concurrent kernel execution in different non default streams, actually I don’t know how I can launch them together, if someone could explain how this is possible it would be great
from timeit import default_timer as timer
import numba
from numba import jit, float64
from numba import cuda
import numpy as np
from numpy import *
stream1 = cuda.stream()
stream2 = cuda.stream()
nx = 20000
ny = 1000
ly = ny-1
uLB = 0.04
cx = np.array([0, 1,-1, 0, 0, 1,-1, 1,-1],dtype=np.float64);
cy = np.array([0, 0, 0, 1,-1, 1,-1,-1, 1],dtype=np.float64);
c = np.array([cx,cy]);
w = np.array([4/9, 1/9, 1/9, 1/9, 1/9, 1/36, 1/36, 1/36, 1/36],dtype=np.float64);
def inivel(d, x, y):
return (1-d) * uLB * (1 + 1e-4*sin(y/ly*2*pi))
@cuda.jit
def equilibrium_gpu(rho,u,c,w,feq):
nx2 = rho.shape[0]
ny2 = rho.shape[1]
cuda.syncthreads()
j, k = cuda.grid(2)
if (j < nx2) & (k < ny2):
for i in range(9):
feq[i, j, k] = rho[j,k]*w[i] * (1 + (3 * (c[0,i]*u[0,j,k] + c[1,i]*u[1,j,k])) + 0.5*(3 * (c[0,i]*u[0,j,k] + c[1,i]*u[1,j,k]))**2 - (3/2 * (u[0,j,k]**2 + u[1,j,k]**2)))
cuda.syncthreads()
vel = fromfunction(inivel, (2,nx,ny))
rho = np.ones([nx, ny], dtype='float64')
res = np.zeros([9, nx, ny], dtype='float64')
feq = np.zeros((9,nx,ny))
############# first 1/4 ################
rho1 = rho[:5000]
vel1x = vel[0,:5000,:]
vel1y = vel[1,:5000,:]
vel1 = np.array([vel1x,vel1y])
rho1_device = cuda.to_device(rho1, stream=stream1)
u1_device = cuda.to_device(vel1, stream=stream1)
c1_device = cuda.to_device(c, stream=stream1)
w1_device = cuda.to_device(w, stream=stream1)
feq1_device = cuda.device_array(shape=(D,int(nx/4),ny,), dtype=np.float64, stream=stream1)
############# second 1/4 ################
rho2 = rho[5000:10000]
vel2x = vel[0,5000:10000,:]
vel2y = vel[1,5000:10000,:]
vel2 = np.array([vel2x,vel2y])
rho2_device = cuda.to_device(rho2, stream=stream2)
u2_device = cuda.to_device(vel2, stream=stream2)
c2_device = cuda.to_device(c, stream=stream2)
w2_device = cuda.to_device(w, stream=stream2)
feq2_device = cuda.device_array(shape=(D,int(nx/4),ny,), dtype=np.float64, stream=stream2)
threadsperblock1 = (8, 128)
blockspergrid_x1 = math.ceil((nx/4) / threadsperblock[0])
blockspergrid_y1 = math.ceil(ny / threadsperblock[1])
blockspergrid1 = (blockspergrid_x1, blockspergrid_y1)
s = timer()
cuda.synchronize()
equilibrium_gpu[blockspergrid1, threadsperblock1,stream1](rho1_device,u1_device,c1_device,w1_device,feq1_device);
equilibrium_gpu[blockspergrid1, threadsperblock1,stream2](rho2_device,u2_device,c2_device,w2_device,feq2_device);
cuda.synchronize()
gpu_time = timer() - s
print(gpu_time)
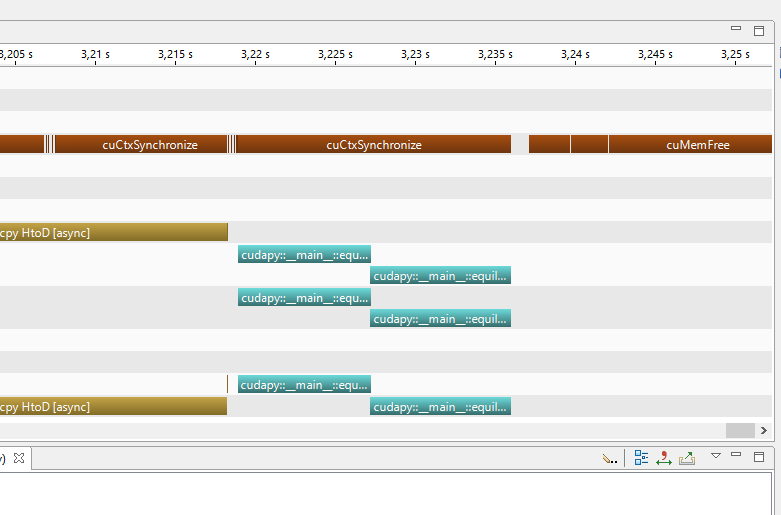
what I get when I look at nvvp is