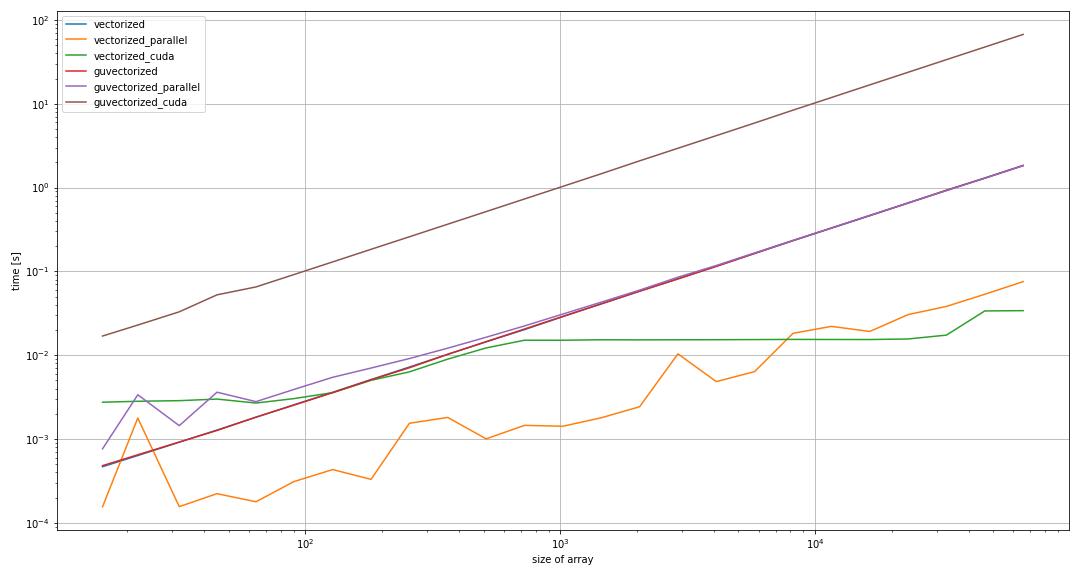
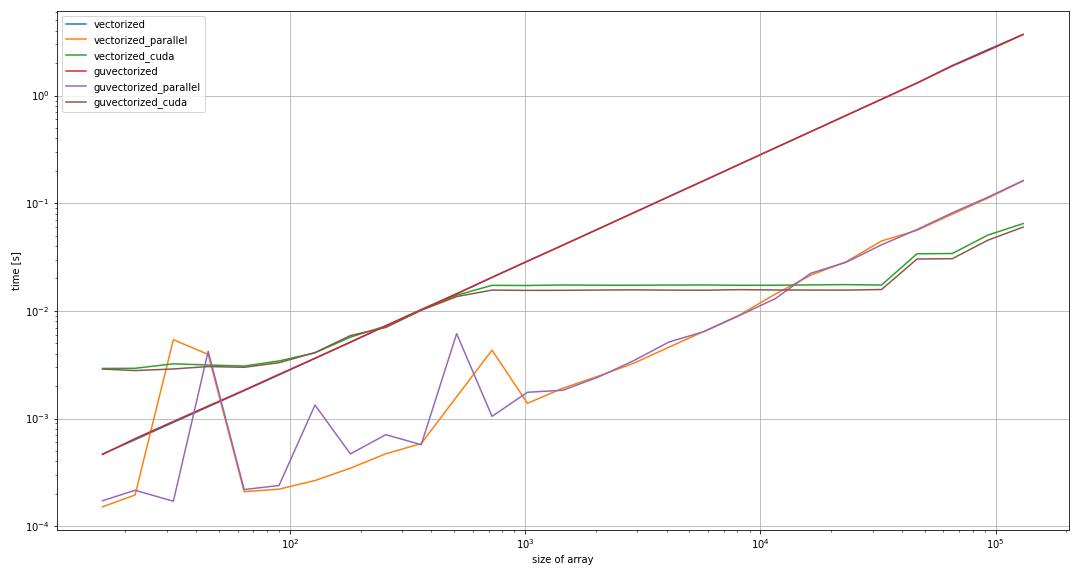
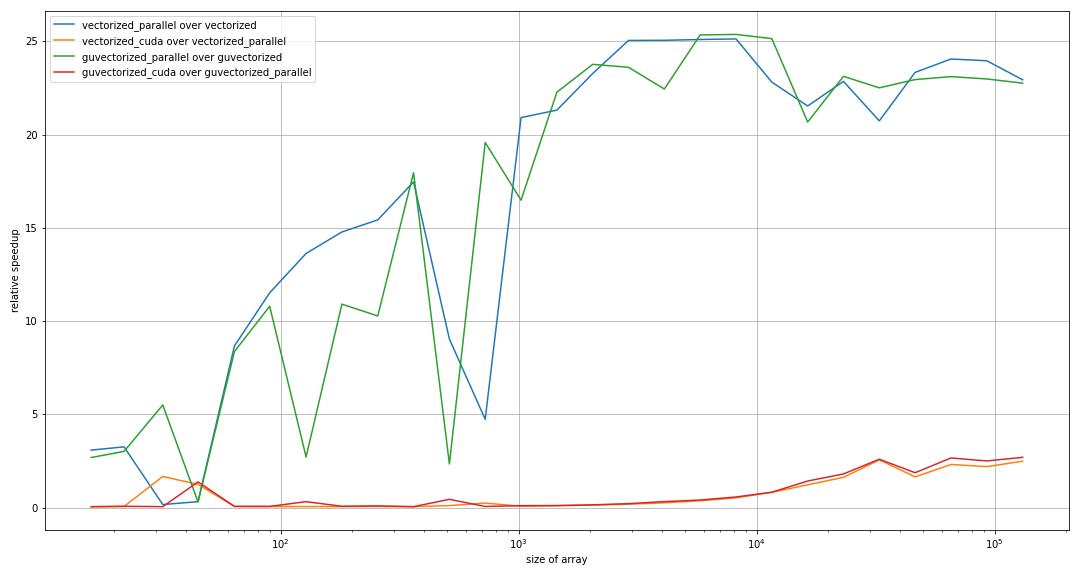
I have just benchmarked a relatively simple workload for both vectorize and guvectorize across all targets (cpu, parallel and cuda) across different sizes of input arrays.
On the vectorize size, stuff is as expected: For sufficiently large input arrays, I can saturate all my cores with target parallel. Performance scales accordingly. cuda is yet a little faster than all the CPU cores, again as expected.
guvectorized for targets cpu and parallel is basically as fast as vectorize for target cpu. It does not benefit from multiple cores, with and without the use of prange? Even more interestingly, when I switch guvectorized to target cuda, it gets more than a solid order of magnitude slower than a single CPU core?
Test workload looks somewhat like this:
COMPLEXITY = 2 ** 11
@jit(*args, **kwargs)
def helper(scalar: float) -> float:
res: float = 0.0
for idx in range(COMPLEXITY):
if idx % 2 == round(scalar) % 2:
res += sin(idx)
else:
res -= cos(idx)
return res
@vectorize(*args, **kwargs)
def v_main(d: float) -> float:
return helper(d)
@guvectorize(*args, **kwargs)
def gu_main(d, r):
for idx in [nb.p]range(d.shape[0]):
r[idx] = helper(d[idx])
Whatever loops one places inside a function decorated by guvectorize do not get parallelized. That’s key. So my initial workaround simply restricts the loop in my initial function to one iteration, allowing the parallelization on other dimensions to kick in. Before, there was nothing to parallelize: Everything was handled by a sequential for loop inside the function - which perfectly explains the bad benchmark results I initially observed.
Perhaps this could be made a bit more clear in the documentation … ?
The warning that Numba emitted was also pointing to this:
/home/ernst/Desktop/PROJEKTE/prj.TST2/github.poliastro/env310/lib/python3.10/site-packages/numba/cuda/dispatcher.py:488: NumbaPerformanceWarning: Grid size 1 will likely result in GPU under-utilization due to low occupancy.
warn(NumbaPerformanceWarning(msg))
Perhaps for gufuncs this warning could also point a bit more specifically to the relationship between grid size and the input shape.